


医学院 新闻动态
4月14日,西湖大学医学院郭天南团队联合西湖欧米团队在Nature Communications发表了最新AI蛋白质组研究成果,推出首个预训练DIA蛋白质谱AI模型DIA-BERT,显著提升DIA蛋白质组鉴定深度。
文章链接:
https://www.nature.com/articles/s41467-025-58866-4

图1 论文截图
提纲挈领
近年来,DIA质谱已成为定量蛋白质组研究的主要方法,但是其复杂的数据分析一直是领域难点。如何从DIA质谱数据中对尽可能多的蛋白质进行鉴定和准确定量,是蛋白质组领域的研究热点,对临床蛋白质组转化具有重要价值。
本研究首次将一种基于预训练变换器(Transformer)模型BERT引入DIA蛋白质谱数据分析,开发出全新的分析软件DIA-BERT。该工具先使用已有的DIA数据进行预训练,然后通过模型微调,显著提升了蛋白质组的鉴定深度,尤其在低丰度蛋白质的识别和定量分析上表现出色,为DIA蛋白质组数据分析设定了新的标杆。
近年来,数据非依赖性采集(DIA)质谱技术已成为高通量定量蛋白质组的最重要的手段。然而,DIA数据的复杂性和大规模数据的处理需求使得其分析面临诸多挑战。
DIA蛋白质组产生的质谱数据高度复杂,数以千百计的蛋白质片段的谱图数据交织在一起,人类无法识别,只有通过AI去卷积才能能够实现数据分析。既有的DIA数据分析软件层出不穷,极大地推动了定量蛋白质组领域的发展,但是它们仍存在多个技术限制,例如依赖独立的文件的特征提取、缺乏跨样本数据共享的能力、以及相对简单的机器学习模型,导致蛋白质组鉴定深度有限。
因此,如何进一步提升DIA数据分析的深度,是蛋白质组领域亟待解决的问题,成为领域热点。
本研究以Google开发的基于Transformer的BERT语言模型为基础,针对DIA蛋白质组,构建了一套全新的“端到端”预训练模型,包括一个蛋白质鉴定的模型和一个蛋白质定量的模型。
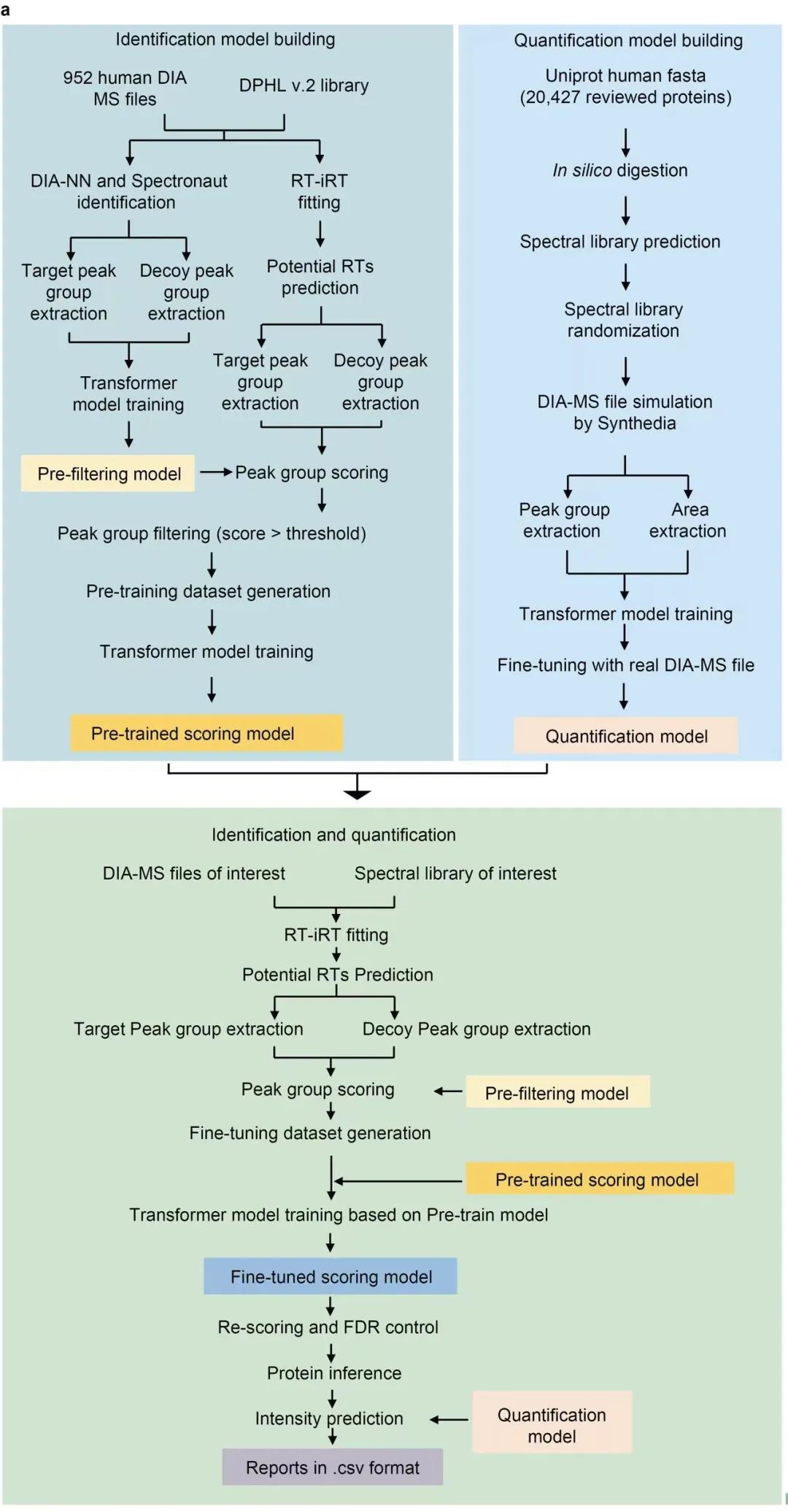
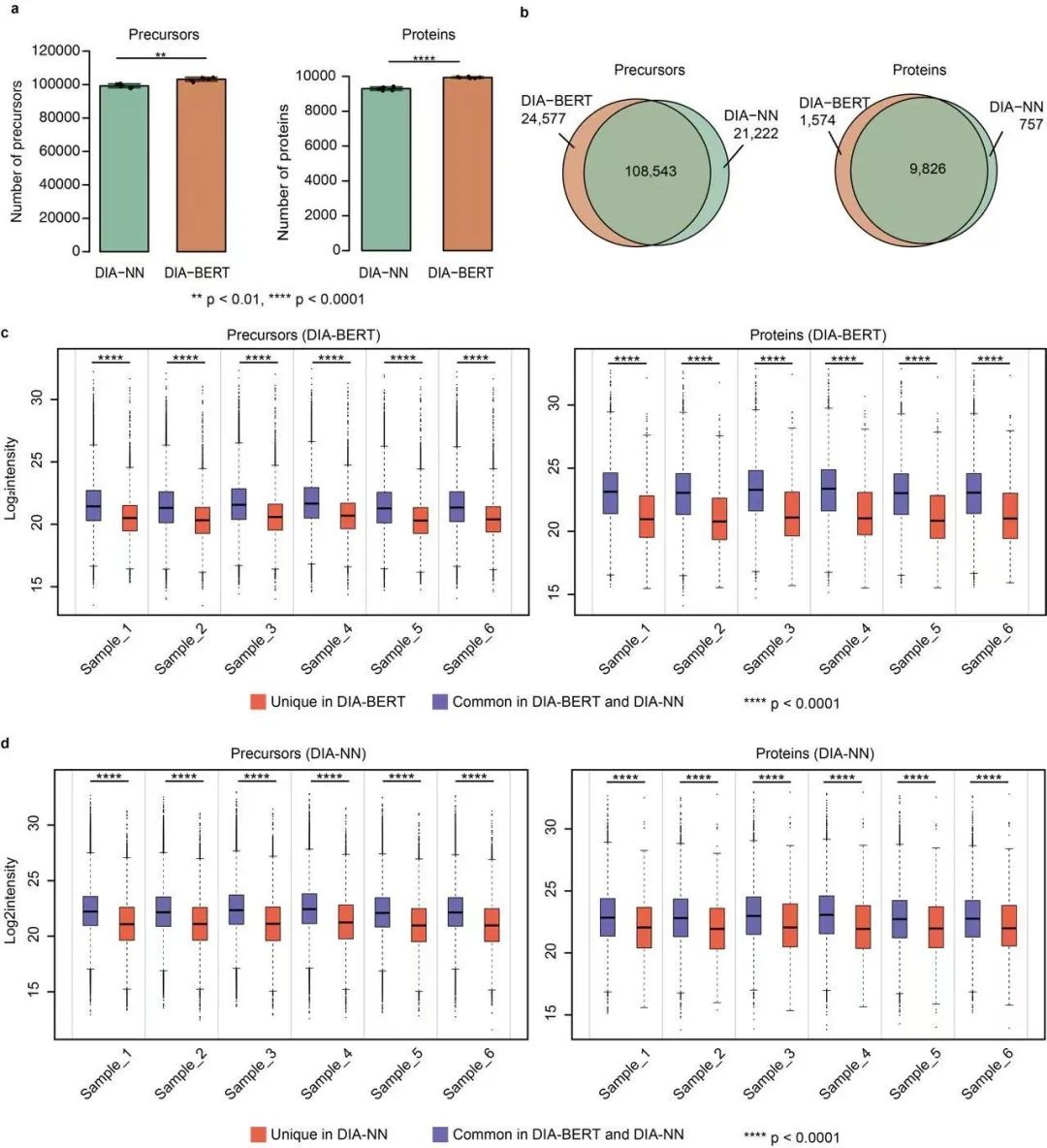
1. 蛋白质组鉴定深度的比较
在使用两物种谱库方法的条件下,DIA-BERT在所有测试的DIA文件中均优于DIA-NN,且保持了低于0.01的保守假发现率(FDR)。
在上述五种癌症样本中,DIA-BERT在肽段母离子的识别数量上比DIA-NN平均高出22%,在蛋白质的识别数量上高出51%。
同时,DIA-BERT能够回溯识别DIA-NN已识别的80%肽段母离子和98%蛋白质,证明其对DIA数据有较强的捕捉能力。
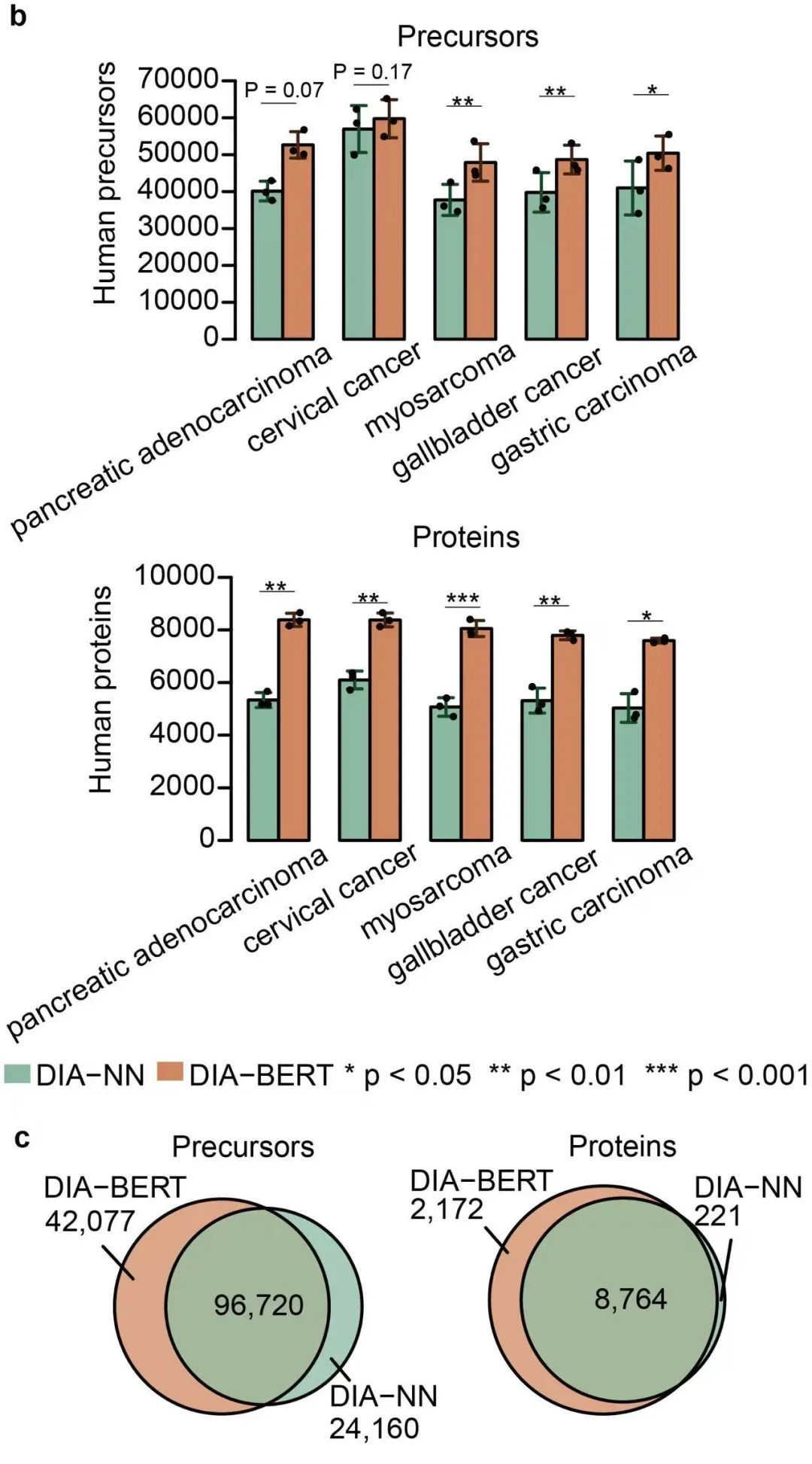
2. 蛋白质组鉴定的稳定性比较
3. 低丰度蛋白质的鉴定
研究进一步分析了含有多个多肽母离子的蛋白和只含有单个多肽母离子的蛋白质,发现在这两类蛋白质中,DIA-BERT都比DIA-NN识别更多的蛋白质,平均提高了150%。即使去除“单肽蛋白”,DIA-BERT仍能识别29%更多的蛋白质,且这一结果在统计上显著。
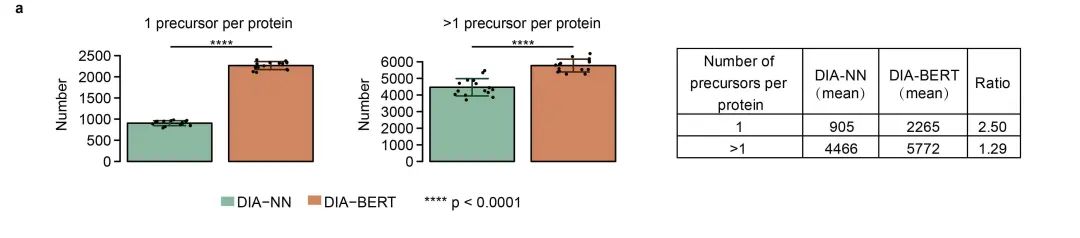
4. DIA-BERT对低丰度蛋白质的识别能力
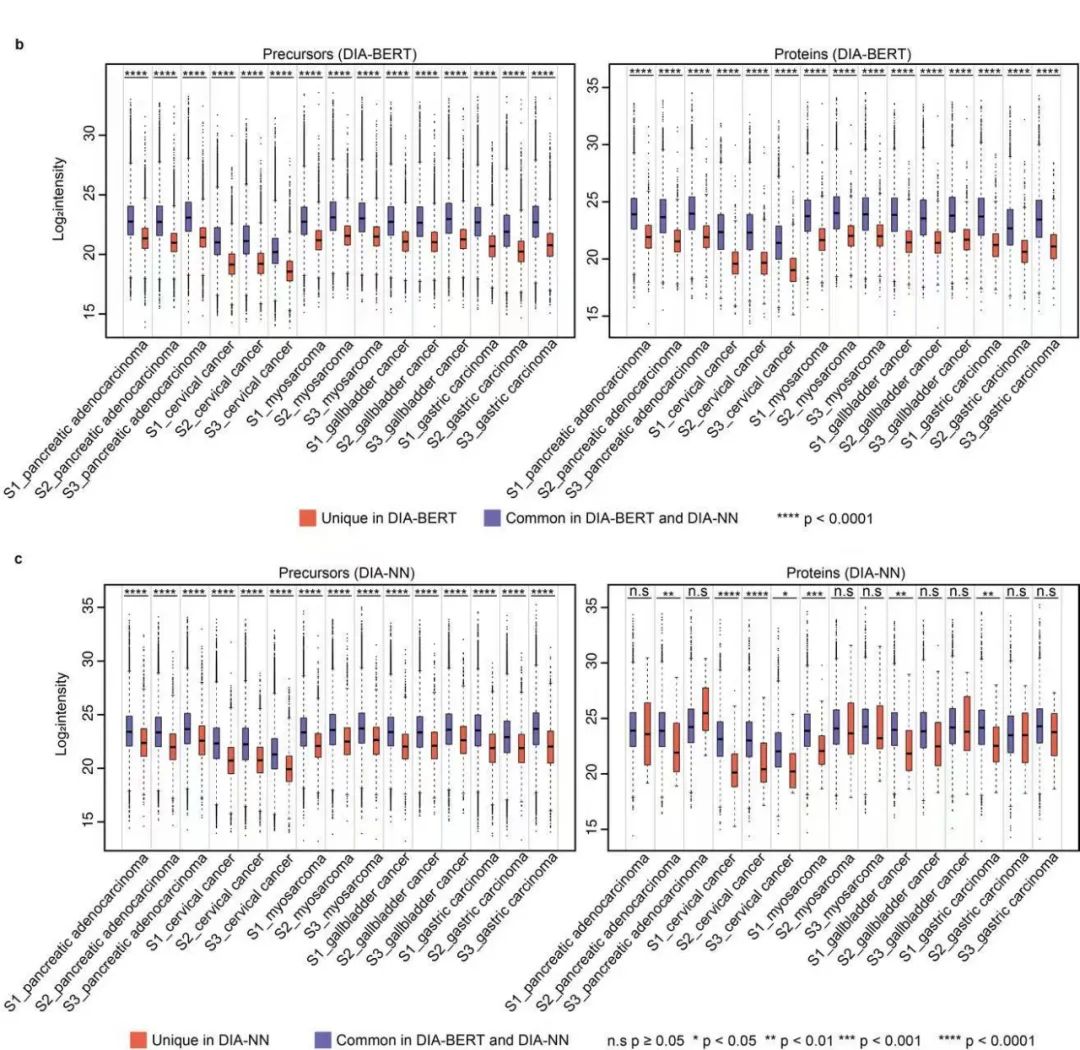
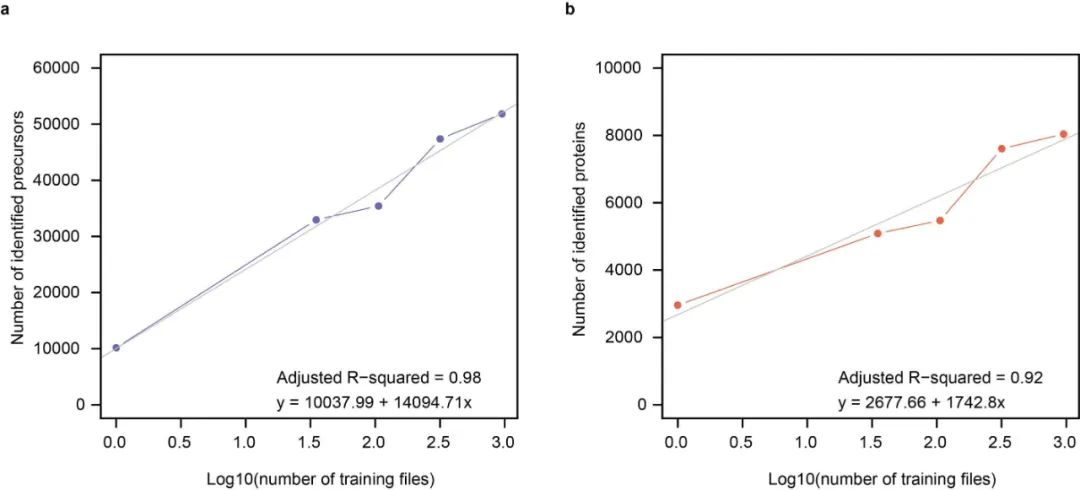
5. 进一步增加预训练数据的量有望进一步提升DIA-BERT的分析能力
由于DIA-BERT是首个基于预训练的DIA蛋白质组模型,研究团队还探讨了训练数据量对其性能的影响。数据显示,逐渐增加训练数据的数量,DIA-BERT的表现直线提升,并且直到我们使用952个DIA文件进行训练,也没有达到平台期,表明今后我们仍可以通过增加DIA预训练数据的数量进一步提升DIA-BERT的分析能力。
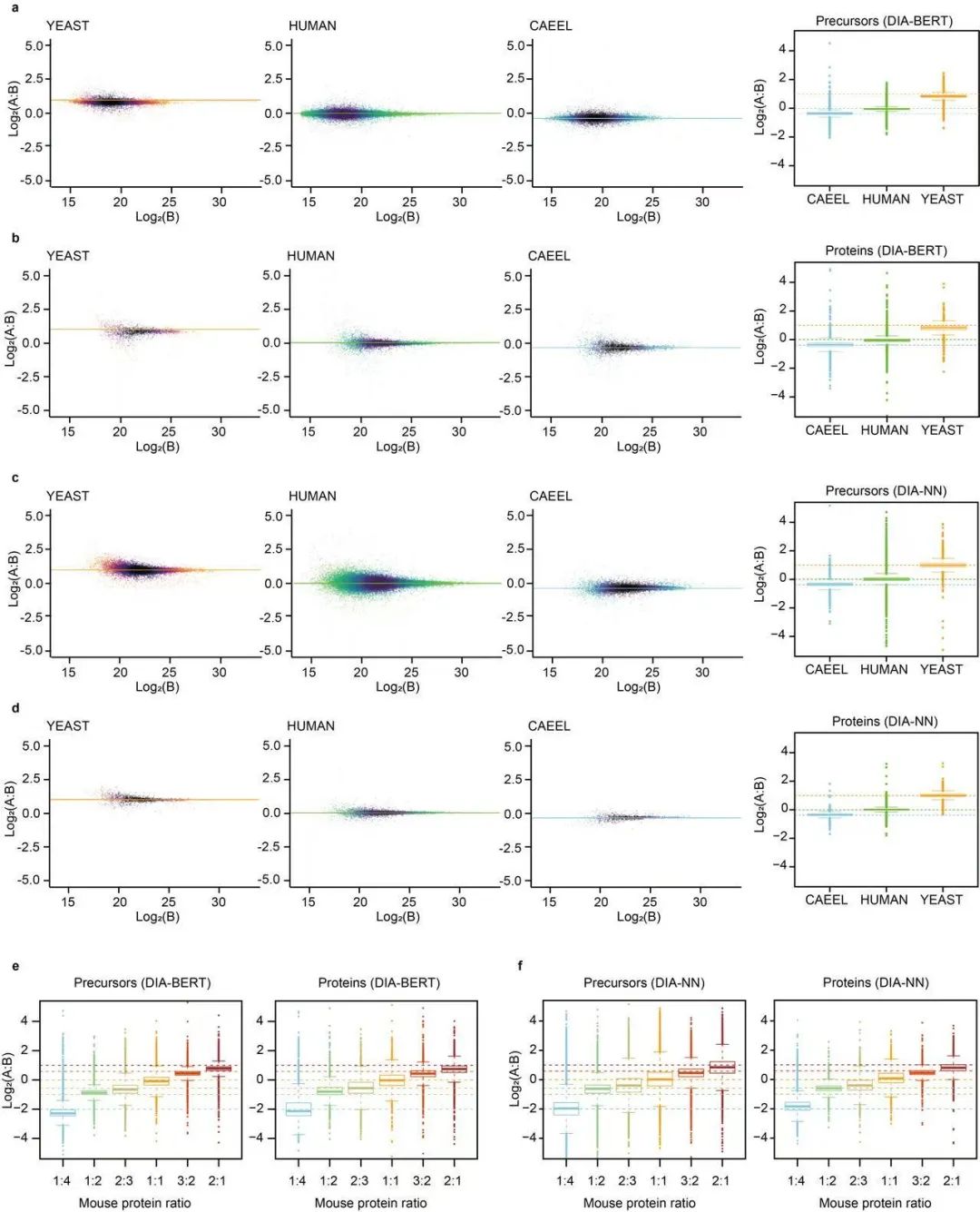
6. 从分析人的蛋白质组延伸到分析其他物种的蛋白质组
研究表明,虽然DIA-BERT的模型使用来源于人组织的DIA预训练数据集,但是具有较强的泛化性。数据显示,除了可以分析人的蛋白质组数据,DIA-BERT还可以分析来自于酵母和秀丽隐杆线虫的蛋白质组,并且优于DIA-NN。其对低丰度蛋白质具有良好鉴定和定量能力,也适用于多种物种的蛋白质组数据分析。
7. 定量分析:DIA-BERT的定量精度
本研究还开发了一种基于Transformer模型的峰面积估计算法,用以提升DIA-MS数据的定量精度。
8. 用户界面与功能
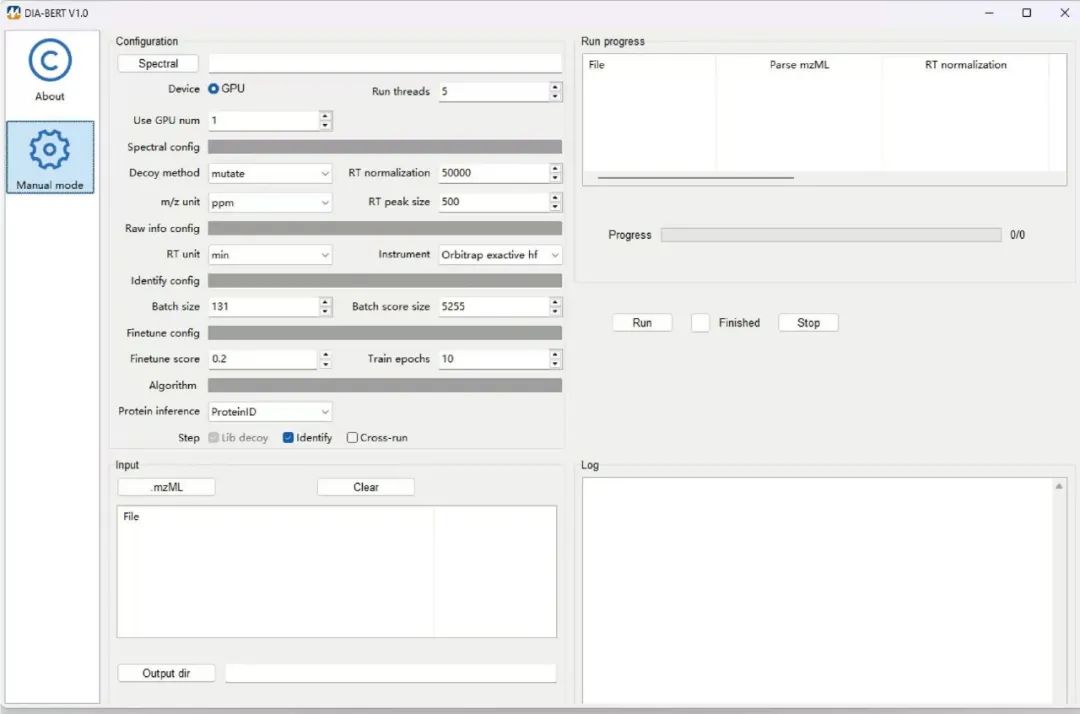
图9
DIA-BERT显著提高了DIA-MS数据中肽段母离子和蛋白质的识别准确性和灵敏度,并在定量分析中展现了强大的能力。
通过预训练Transformer模型的创新应用,DIA-BERT为蛋白质组学领域提供了一种新的端到端预训练AI模型,其鉴定深度高,定量准确度高,特别是在低丰度蛋白质的识别和定量分析方面具有明显的优势。此外,这个软件针对学术用户开源,其良好的可扩展性使其成为一个极具潜力的工具。更多信息可以访问:https://guomics.com/DIA-BERT/
西湖大学医学院助理研究员刘志伟为论文第一作者,西湖欧米AI工程师刘谱和西湖大学医学院助理研究员孙莹莹为共同第一作者,西湖实验室AI科学家陈义为共同通讯作者。
课题受到了科技部重点研发计划、国家自然科学基金、浙江省 “尖兵领雁+X” 研发攻关计划、西湖大学未来产业研究中心和西湖教育基金会的资助和支持,项目得到了西湖大学高性能计算中心的支持和帮助。














