


医学院 新闻动态
循环血液蛋白质组被视为发现疾病标志物、理解疾病机制、实现精准医疗的“金矿”。然而,一个巨大挑战横亘在科学家面前,那就是如何整合和比较来自全球不同实验室、使用不同技术平台产生的海量却“碎片化”的血液蛋白质数据。
2025年9月23日,由西湖大学医学院郭天南教授、德国格赖夫斯瓦尔德大学 Uwe Völker 教授、美国 Cedars Sinai 医学中心 Jennifer Van Eyk 教授和瑞典皇家理工学院 Jochen M. Schwenk 教授领衔,联合全球数十家顶尖机构的科学家,在Nature Genetics发表了一篇具有里程碑意义的观点文章。他们深刻剖析当前血液蛋白质组学研究的标准化困境,首次系统性提出一个可行动的解决方案。
原文链接:
https://www.nature.com/articles/s41588-025-02319-7

图1 文章截图
01
数据为何难以“对话”?三大核心痛点
技术平台“百花齐放”但“方言各异”。血液蛋白质组的两大主要方法,质谱技术和亲和技术,其原理不同,鉴定和定量的蛋白质也差异巨大。研究显示,即使分析同一份样本,不同平台检测到的相同蛋白质极少(~30%),数据定量相关性也很低(~0.3)。
实验流程“千差万别”。从抽血管选择、样本处理保存,到前处理方法、不同仪器和数据分析软件,每一步操作的微小差异都会给最终结果带来显著波动(图2)。

缺乏统一的“标尺”。没有全球公认的高质量标准参照样本,不同研究产生的数据就像讲着不同方言,无法有效沟通整合。这使得多个血浆蛋白质组学的宝贵数据成为“信息孤岛”。
02
破局之道:构建标准化“桥梁”
文章的核心提议是在未来的每项研究中都加入共享的标准参照样本,并利用“样本-参照比率”计算方法进行数据整合。
两类“万能标尺”

图3 参考样品在实现不同循环血液蛋白质组数据集之间可比性方面的潜力
03
行动计划与未来蓝图
启动阶段优先联合权威计量机构,建立全球共享的供体血浆库。
精选20-30个核心血液蛋白,加入其同位素标记版本作为“内参卫士”。
建议每个实验批次必须包含3-4份参照样本,用于校正实验和数据分析的批次效应。
倡导将参照样本数据作为研究数据的一部分公开共享。 预计此举仅增加约5%的检测成本,但带来的数据整合价值远超投入。
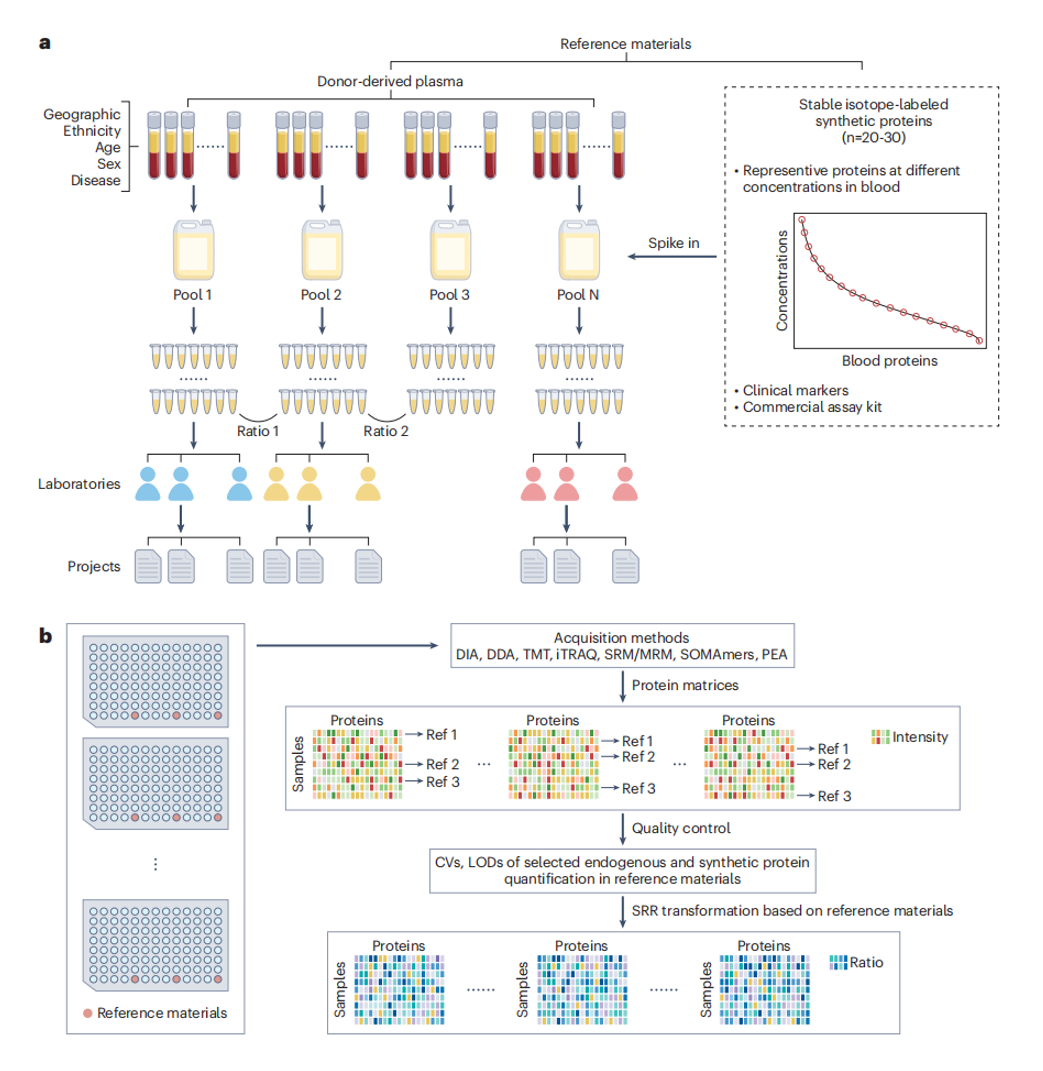
图4 循环血液蛋白质组学研究中参考物质的初步标准化框架
04血液蛋白质组学标准化新框架
解锁数据金矿,让海量数据能与全球研究无缝整合,挖掘更深层次的生物学奥秘。 加速临床转化,提高生物标志物研究的可靠性和效率,推动血液蛋白质检测更快进入临床应用。 推动技术进化,为评估新旧平台性能提供客观基准。 奠定全球协作基石,由中国科学家牵头,欧美多国顶尖团队共同参与,在HUPO组织支持下,为全球数据共享建立新范式。
结语
构建循环血液蛋白质组学的标准化参照框架,不仅是技术层面的优化,更是推动该领域发展、实现精准医学目标的重要基础。这一由国际研究团队提出的初步方案,为整合现有数据资源、建立统一的分析标准迈出了关键的第一步,为后续研究奠定了基础。
西湖大学医学院郭天南课题组 (guomics.com) 长期从事蛋白质组学相关研究,联合人工智能,解析生物过程的原理,助力疾病诊疗。团队诚邀有志于AIVC研究的优秀本科生、研究生及博士后研究人员加盟!














